Globally-Robust Instance Identification and Locally-Accurate Keypoint Alignment for Multi-Person Pose Estimation
Fangzheng Tian, Sungchan Kim
Abstract
Scenes with a large number of human instances are characterized by significant overlap of the instances with similar appearance, occlusion, and scale variation. We propose GRAPE, a novel method that leverages both Globally Robust human instance identification and locally Accurate keypoint alignment for 2D Pose Estimation. GRAPE predicts instance center and keypoint heatmaps, as global identifications of instance location and scale, and keypoint offset vectors from instance centers, as representations of accurate local keypoint positions. We use Transformer to jointly learn the global and local contexts, which allows us to robustly detect instance centers even in difficult cases such as crowded scenes, and align instance offset vectors with relevant keypoint heatmaps, resulting in refined final poses. GRAPE also predicts keypoint visibility, which is crucial for estimating centers of partially visible instances in crowded scenes. We demonstrate that GRAPE achieves state-of-the-art performance on the CrowdPose, OCHuman, and COCO datasets. The benefit of GRAPE is more apparent on crowded scenes (CrowdPose and OCHuman), where our model significantly outperforms previous methods, especially on hard examples.
It will take some time to load the videos and images when you open the webpage, thank you for your patience.
Demo Videos
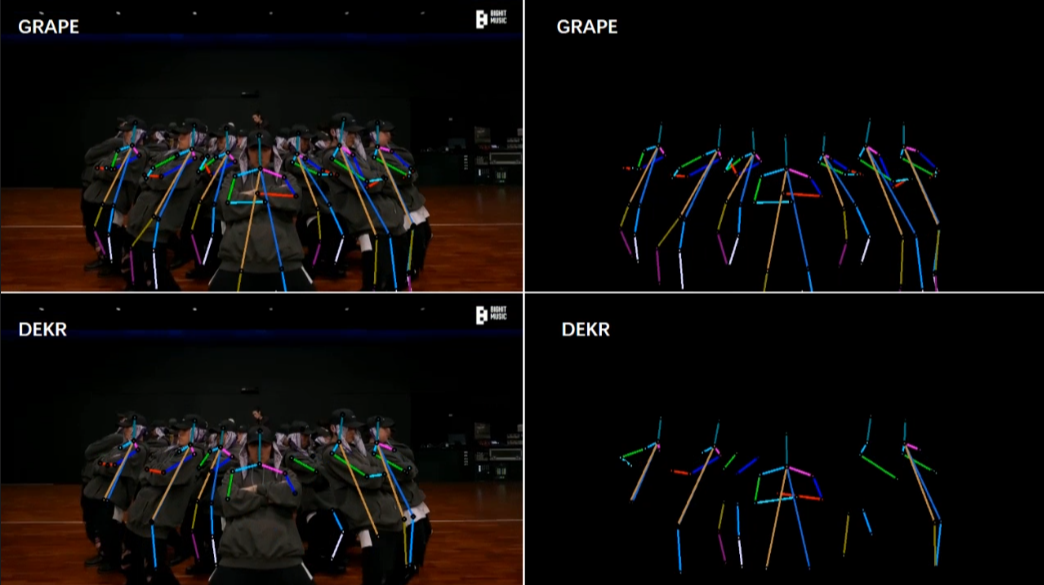
[1/6] -- CrowdPose -- Indoor (Comparison with DEKR [1])
Video Credit: BTS(Run BTS)' Dance Practice
Screenshots of some frames in the video (you can click to enlarge, and use the left and right arrows on your keyboard to view the enlarged image)

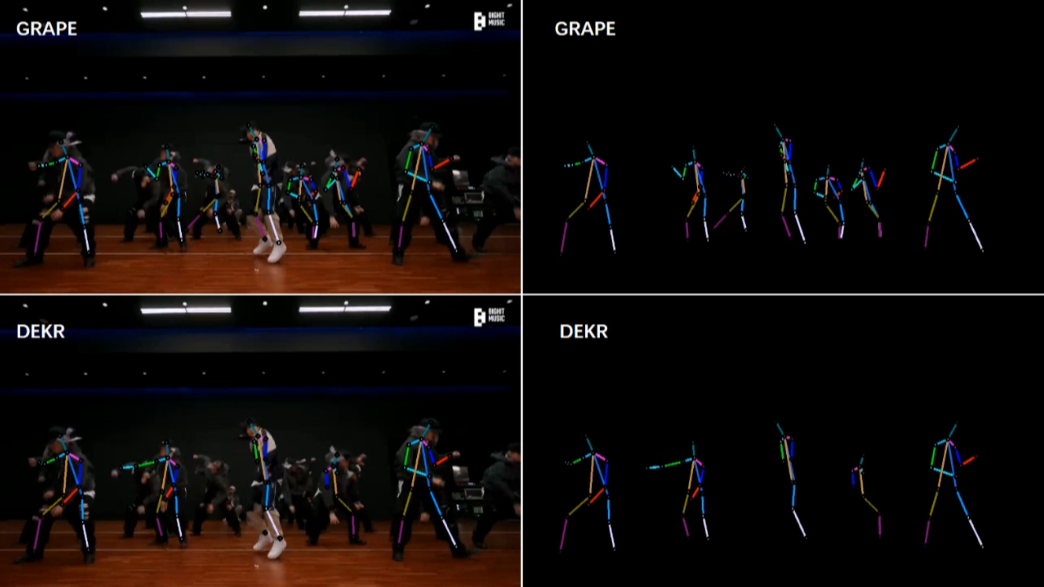
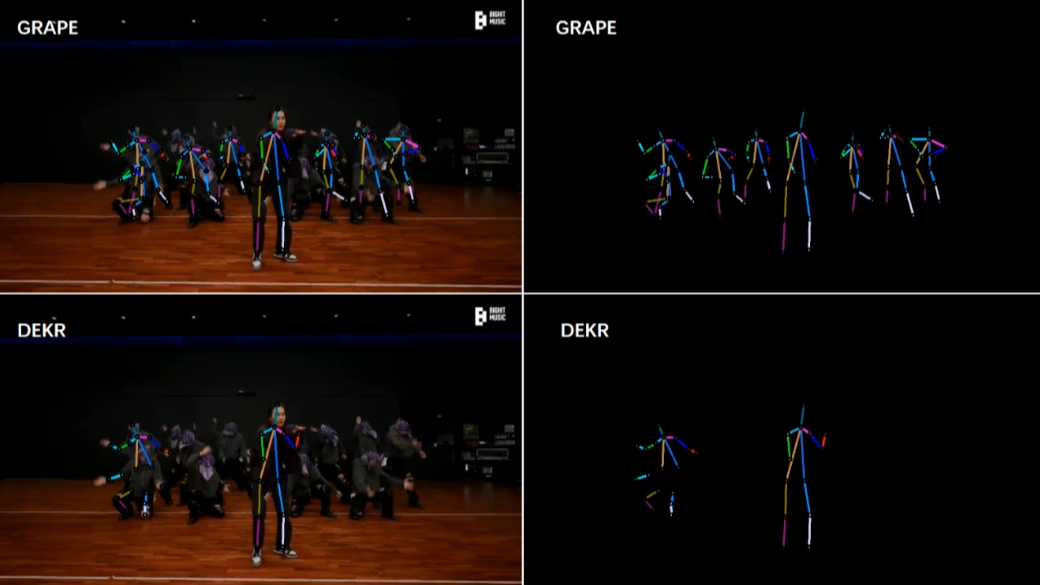
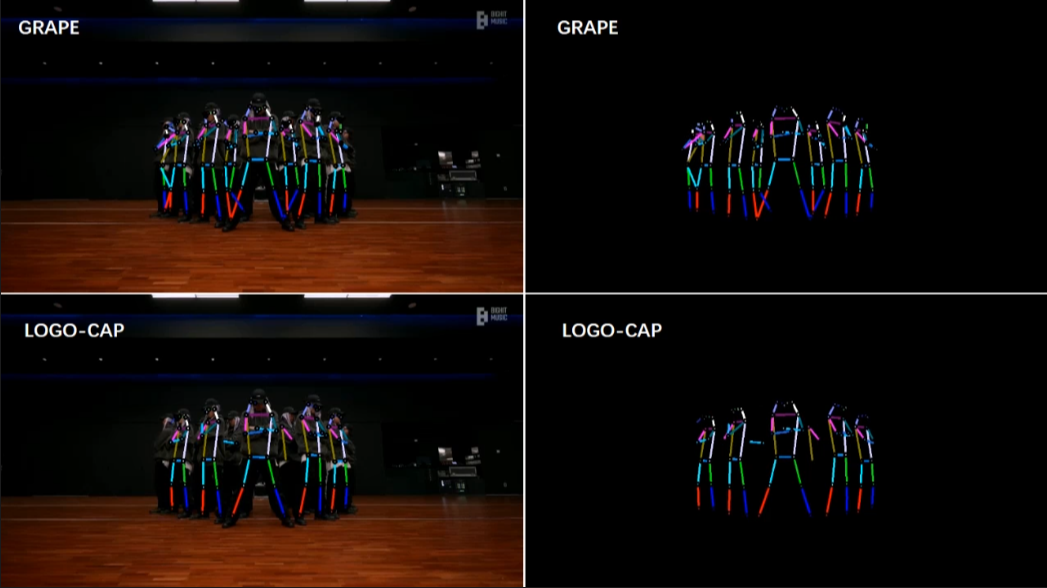
[2/6] -- COCO -- Indoor (Comparison with LOGO-CAP [2])
Video Credit: BTS(Run BTS)' Dance Practice
Screenshots of some frames in the video (you can click to enlarge, and use the left and right arrows on your keyboard to view the enlarged image)
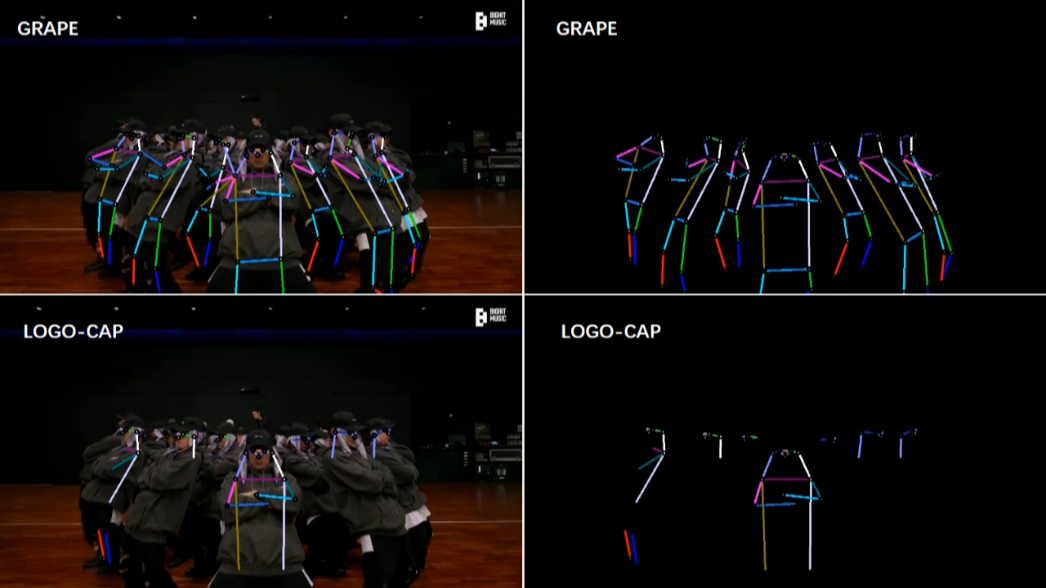
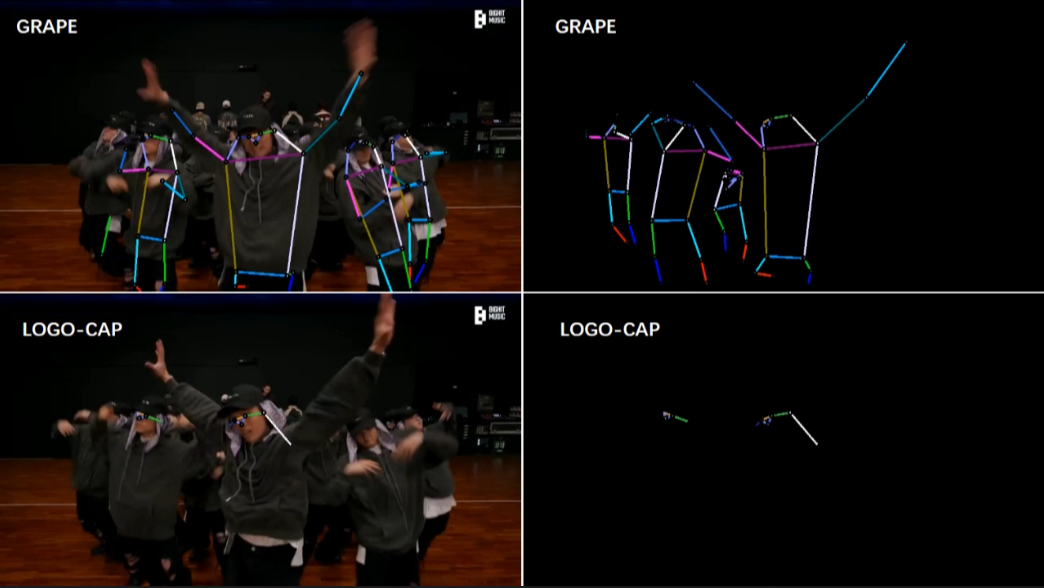
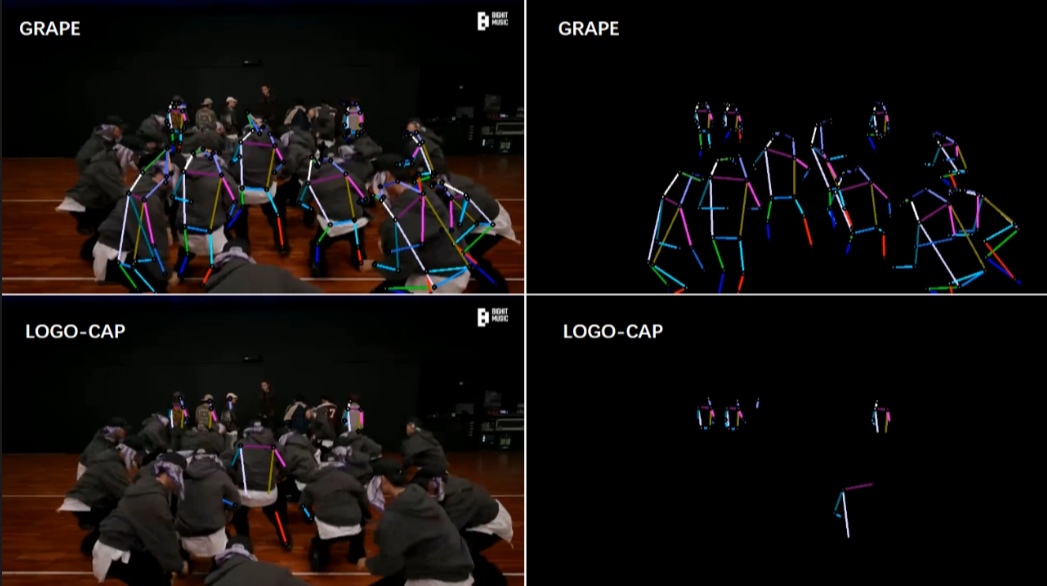
[3/6] -- CrowdPose -- Cartoon (Comparison with DEKR [1])
Video Credit: Animation Zootopia music video
Screenshots of some frames in the video (you can click to enlarge, and use the left and right arrows on your keyboard to view the enlarged image)




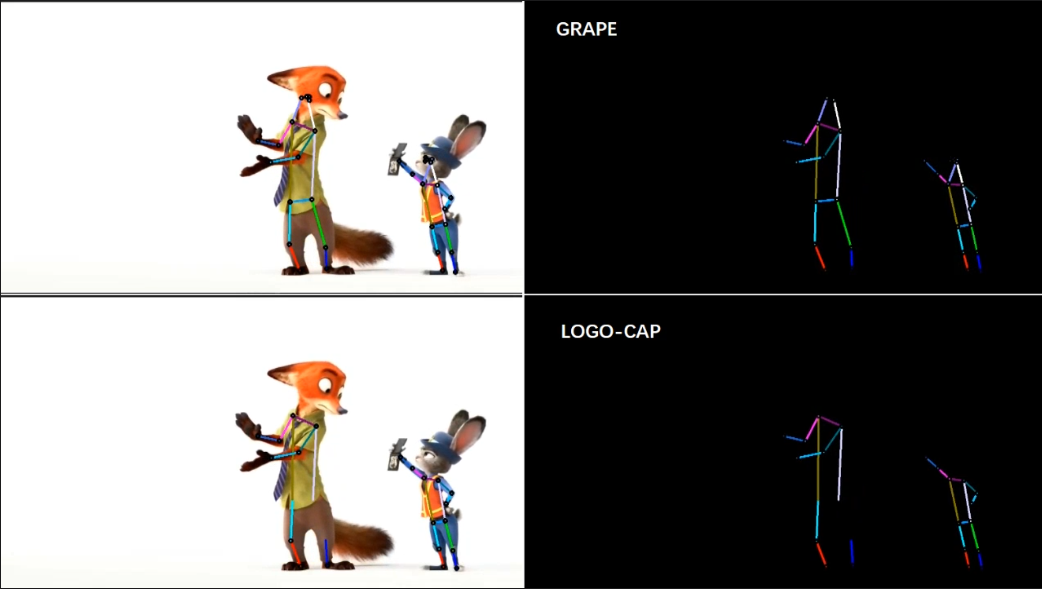
[4/6] -- COCO -- Cartoon (Comparison with LOGO-CAP [2])
Video Credit: Animation Zootopia music video
Screenshots of some frames in the video (you can click to enlarge, and use the left and right arrows on your keyboard to view the enlarged image)


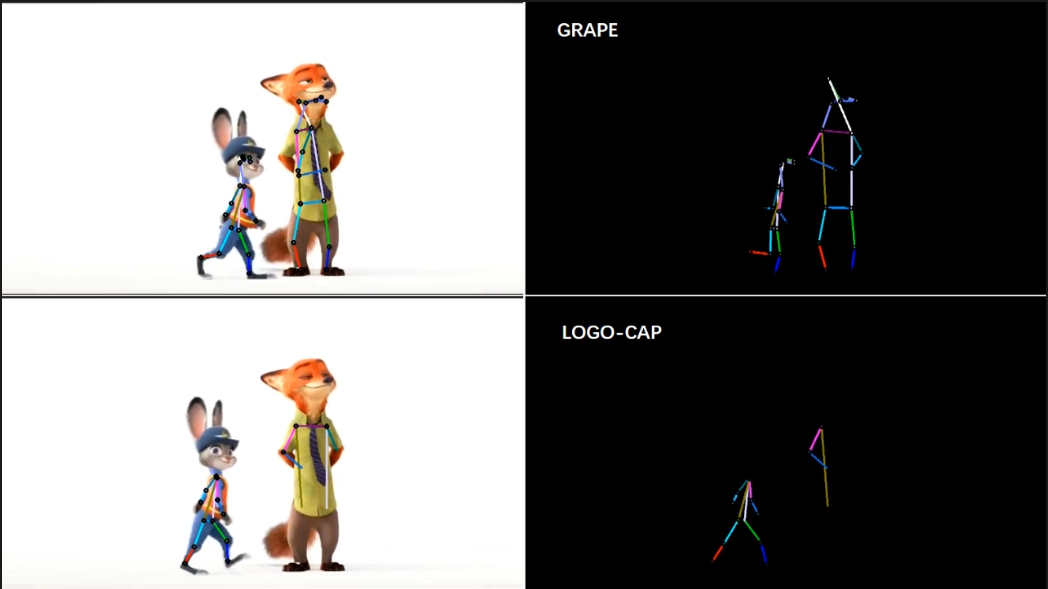
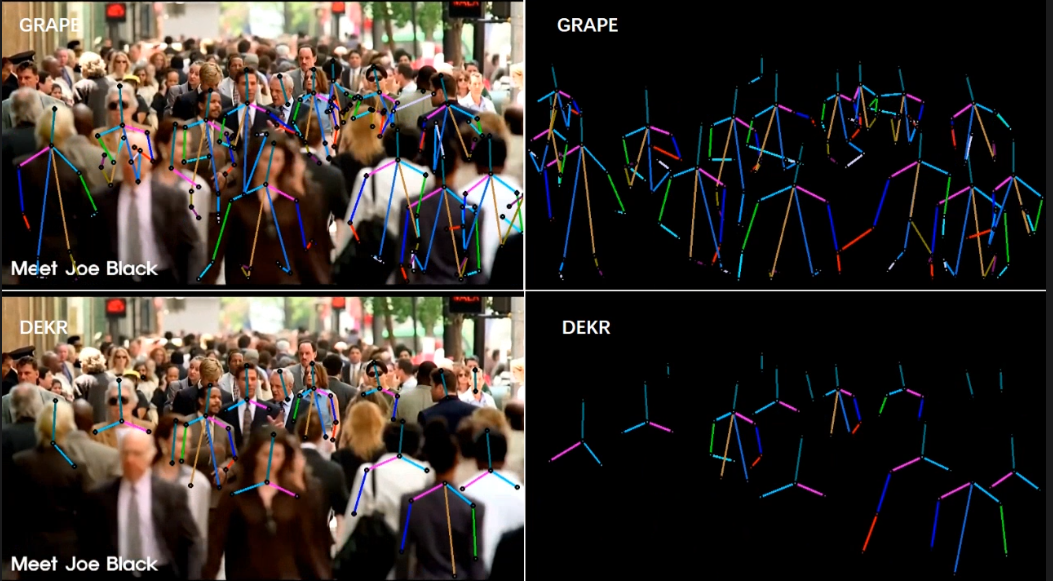
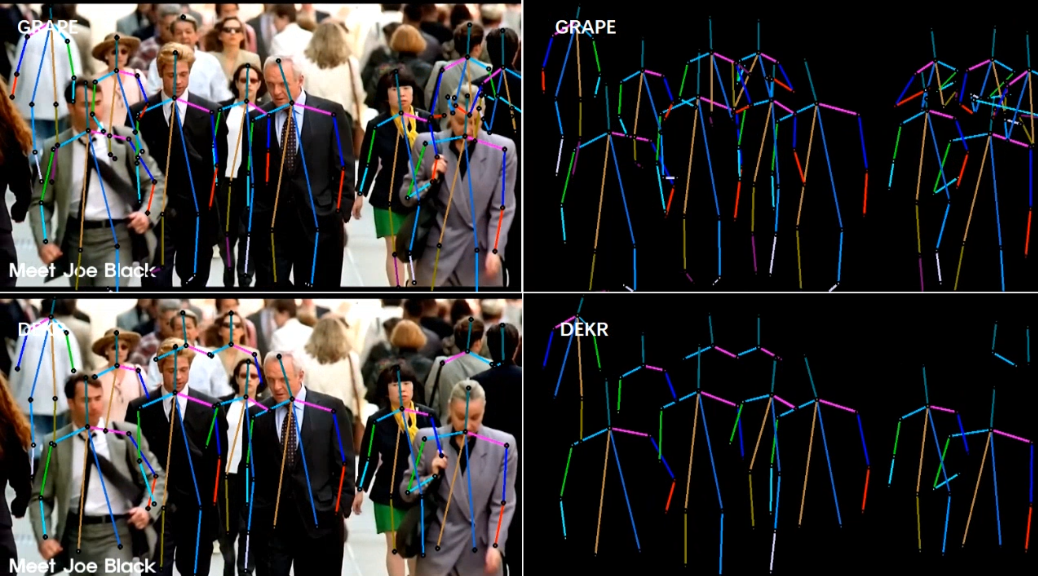
[5/6] -- CrowdPose -- Outdoor (Comparison with DEKR [1])
Video Credit: Street Crowd in New York
Screenshots of some frames in the video (you can click to enlarge, and use the left and right arrows on your keyboard to view the enlarged image)

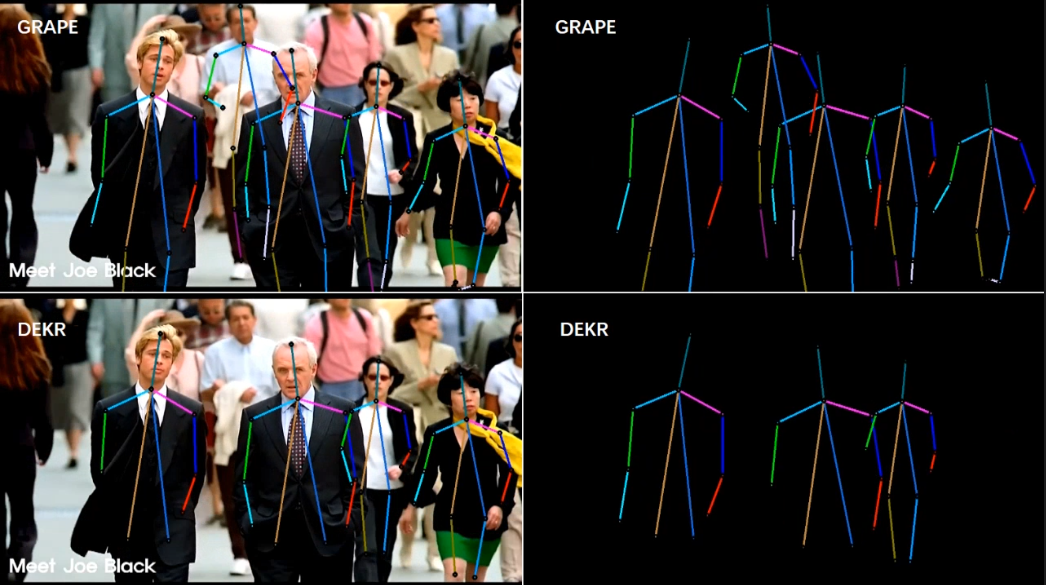
[6/6] -- COCO -- Outdoor (Comparison with LOGO-CAP [2])
Video Credit: Street Crowd in New York
Screenshots of some frames in the video (you can click to enlarge, and use the left and right arrows on your keyboard to view the enlarged image)
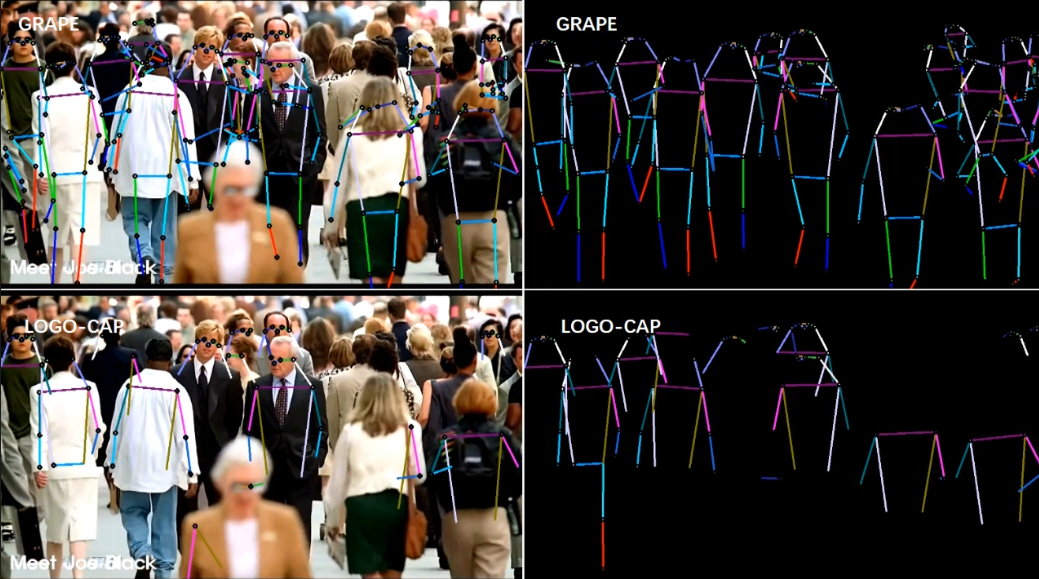
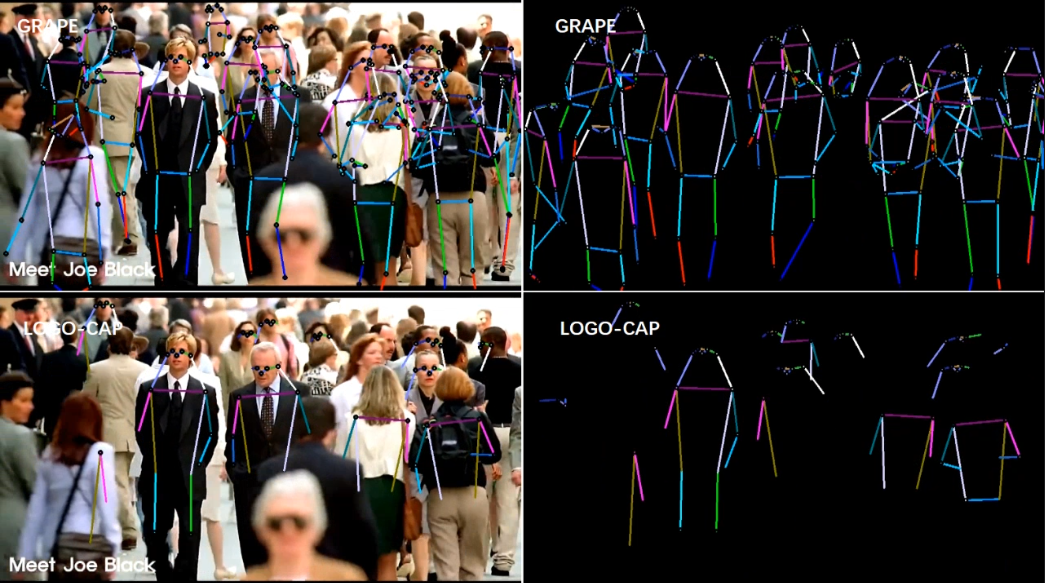
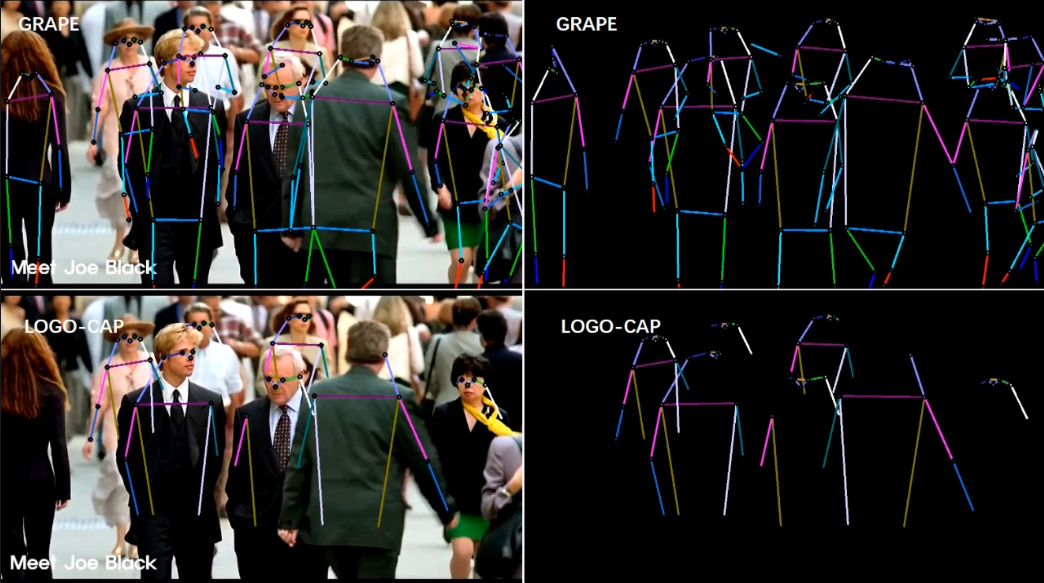

Qualitative Results
For easy viewing of details. Click on the image in this section to make it full screen. In full-screen mode, you can use the mouse wheel to zoom in on the image and drag the mouse to view the details. Press 'Esc' to exit full screen mode.
Figure M1 and Figure M2 are from Figure 5 and Figure 6 in the manuscript. We paste the relevant content as follows.
We provide examples of qualitative evaluation to demonstrate the advantages of our model over recent work by HigherHRNet [3], DEKR [1], and LOGO-CAP [2]. Figure M1 shows that DEKR [9] misses the keypoints of the people due to the low contrast of the image (1st and 2nd examples) or results in incorrect predictions due to the significantly overlapping human bodies (3rd and 4th examples), where GRAPE performs successfully. As shown in Figure M2, existing methods, HigherHRNet [3], DEKR [1], and LOGO-CAP [2], suffer from difficult situations, such as small instances and occlusion due to poor image contrast. While HigherHRNet [3] detects more instances than DEKR [1] and LOGOCAP [2], it performs poorly with instances of similar appearance, leading to unrealistic keypoint groupings (1st example). LOGOCAP [2] misses the most instances while it accurately predicts keypoints for detected instances. In contrast, our method mitigates this difficulty by robustly estimating the centers and scales of human instances, resulting in most instance detection and accurate keypoint prediction.
[1/7]

[2/7]

We provide more qualitative evaluation examples on the three datasets (Figures S1, S2 and S3). We generate qualitative results based on publicly available implementations of HigherHRNet [3], DEKR [1], and LOGOCAP [2]. We set all thresholds used in Section 3.3 of the manuscript to 0.2. Figure S1 shows comparisons of GRAPE with DEKR [1] on the CrowdPose test by training the models on CrowdPose train and val. DEKR [1] misses many keypoints, leading to false matches, where GRAPE effectively avoids these problems. We show additional results of GRAPE by comparing with HigherHRNet [3], DEKR [1] and LOGO-CAP [2] on the COCO val and OChuman test in Figures S2 and S3, respectively. Figure S4 provides failure cases with our model compared to previous methods. We visualize the results of human keypoints predicted from each of the steps in our method in Figure S5.
[3/7]

[4/7]

[5/7]

[6/7]

[7/7]

References
[1] Zigang Geng, Ke Sun, Bin Xiao, Zhaoxiang Zhang, and Jingdong Wang. 2021.Bottom-up human pose estimation via disentangled keypoint regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14676–14686.
[2] Nan Xue, Tianfu Wu, Gui-Song Xia, and Liangpei Zhang. 2022. Learning LocalGlobal Contextual Adaptation for Multi-Person Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13065–13074.
[3] Bowen Cheng, Bin Xiao, Jingdong Wang, Honghui Shi, Thomas S Huang, and Lei Zhang. 2020. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5386–5395.